I. Introducción
En el trabajo diario de Jueces y Magistrados es habitual el uso de modelos o plantillas como estructura de la que partir para dictar una Sentencia. El uso de este tipo de plantillas implica en ocasiones su búsqueda, rellenar los datos y una vez completado, comenzar la labor judicial de valoración de prueba y fundamentación. En general, se trata de una tarea repetitiva y sin ningún valor añadido, más allá de rellenar campos y encontrar el modelo adecuado. Este tipo de cometidos no suelen ocupar mucho tiempo, pero si se multiplica en relación con el número de asuntos que se resuelven diariamente, la magnitud se amplía.
La automatización de procesos suele centrarse en la realización de este tipo de tareas, a saber, tareas repetitivas sin valor añadido. Este tipo de tareas pueden ir desde la transcripción del texto de una denuncia, los nombres de las partes, fechas de interés para el pleito o la búsqueda de la plantilla o párrafo adecuado para cada caso concreto, hasta la búsqueda del modelo o plantilla adecuado para estructurar una Resolución Judicial.
Para solventar todo ello, podemos servirnos de unas pocas líneas de código y ahorrar tiempo a la hora de dictar Resoluciones Judiciales.
II. Creación de Modelos
1. Insertando campos en plantillas
El primer paso a la hora de automatizar la labor jurisdiccional será la creación de modelos de resoluciones. Una selección correcta de modelos genéricos con una gran variedad de supuestos y alternativas, nos permitirá agilizar el proceso de dictado de Resoluciones.
Una vez elaborados los modelos, habrán de crearse los campos dentro de los cuales se introducirán los elementos variantes de cada resolución, a saber, datos, fechas, resultado de actos administrativos, pruebas practicadas etc…
Dado que la finalidad pretendida es crear un ecosistema completo de automatización, tendremos que usar por una parte herramientas gráficas, como un Procesador de Textos, y lenguaje de programación para crear nuestro algoritmo automatizador.
Para poder vincular la programación con los modelos haremos uso de Microsoft Word y de Python.
La idea es que podamos rellenar los campos creados desde un programa aparte y no desde el propio procesador de textos. Para ello, haremos uso de la biblioteca de Python «docx-mailmerge».
El primer paso será crear los campos en la Plantilla, para lo que acudiremos a Insertar Elementos rápidos.

Y crearemos tantos campos como resulten necesarios para la plantilla de que se trate a través de la opción «MergeField».
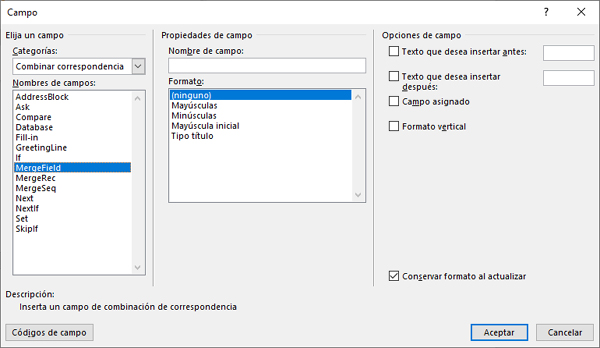
Una vez hayamos creado cada uno de los campos, el texto resultante debería ser semejante al siguiente:

Se aprecian en sombreado los distintos campos, cuyo nombre nos servirá para poder programar la automatización de los mismos.
Una vez creadas las plantillas y los campos en cada una, acudiremos al código para crear un pequeño programa que nos pregunte sobre cada uno de los campos.
2. Vinculando los campos en Python
Para poder ingresar el contenido en los campos de texto de la plantilla, tendremos que llamar a las bibliotecas que nos lo permitan, a saber docx-mailmerge. Para ello, al principio del archivo escribiremos:

Como paso inicial crearemos un programa de línea de commandos que nos pedirá la información de cada uno de los campos y escribiremos las respuestas. Para ello, se preguntará en primer lugar por el número del modelo que se quiere usar, y una vez seleccionado, las preguntas serán diferentes para cada modelo.

En esta sección del código, se preguntará qué modelo usar y en función del mismo, se seleccionará la plantilla a usar, al mismo tiempo preguntará el número y año del procedimiento, a los efectos de los datos de la plantilla y del nombre que tendrá el archivo resultante. Una vez seleccionada la plantilla, habrá que rellenar cada uno de los campos, que podrán ser o no coincidentes según el modelo.

Una vez completados todos los campos, solo quedará plasmarlo en un archivo de texto nuevo, que se guardará con el número y año del procedimiento, con la materia y con el sentido del fallo.
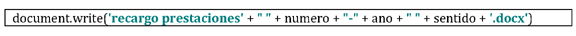
Cuando se ejecute el programa, en una terminal habrá que ir rellenando cada uno de los campos.

Y una vez concluido, se creará un archivo con todos los datos introducidos y con un nombre identificable para el caso.
La utilidad de este programa, sin embargo, resulta muy limitada, dado que hacer uso de una línea de comandos no es la manera más efectiva de trabajar, no hay gráficos, no hay diseños, ni mecanismos de entrada más allá del teclado, por lo que será necesario crear una interfaz gráfica que facilite su uso y ofrezca más alternativas.
III. Creación de una interfaz gráfica
1. Botones reactivos

Para poder hacer uso de los modelos necesitaremos que una interfaz gráfica nos muestre el número de los mismos, así como los distintos supuestos. Para ello usaremos Tkinter, la biblioteca gráfica por defecto de Pyhon. Lo primero será importar las bibliotecas:

Crearemos una ventana, dentro de la cual se situarán los distintos botones. Tomando como ejemplo dos tipos de modelos, a saber, Recargo de Prestaciones y Extinción por voluntad del trabajador, haremos que la selección de cada uno de ellos haga aparecer distintas opciones, como serían, estimatoria, desestimatoria o estimación parcial.
El resultado sería el siguiente:
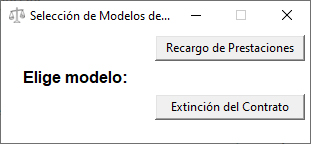
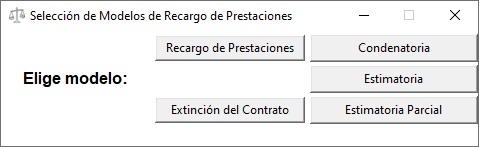

Como se aprecia, cuando se selecciona uno de los modelos iniciales, se amplia la ventana y aparecen tres opciones según el modelo de que se trate, para ello deberemos crear botones, y asignarles funciones, la función de cada botón será que aparezcan sus opciones y desaparezcan las opciones del otro modelo.

Cada botón tiene un comando asignado, es decir, cada vez que se pulsa se ejecuta una acción, en el caso de los botones de «Recargo de Prestaciones» y «Extinción del Contrato», su función será que aparezcan los botones de las alternativas propias de cada modelo y desaparezcan las alternativas de otro modelo. Es acción de aparecer y desaparecer se controla mediante la función grid y grid_forget:

Con esta función, le diremos al programa dónde queremos que aparezca el botón, a saber, en la fila 3 columna 2, o que desaparezca dicho elemento.
Con los botones que aparecen para cada Modelo, se asignará la función de que aparezcan o desaparezcan las entradas de texto propias de cada plantilla.

Mientras que en el primer programa había que introducir los datos dentro de una terminal, en este segundo programa, se introducirán los datos dentro de cajas de texto, con el siguiente resultado:
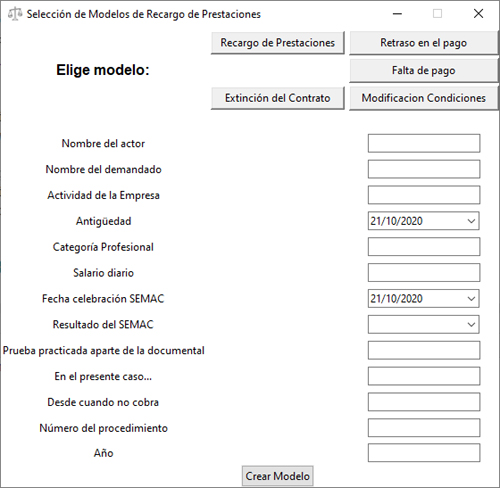
Como se aprecia, aparecen todos los campos que se crearon en la plantilla, con un cuadro de texto para rellenarlos, seleccionar opciones o buscar una fecha.
2. Entradas de texto
Para crear cada entrada de texto habrá que hacer un tk.Entry y un tk.Label, el primero es el cuadro para escribir y el segundo la etiqueta que explica qué es lo que se está rellenando. Ahora bien, para que el texto que se introduce en el cuadro se plasme finalmente en la plantilla del documento, habrá que asignar el texto que se escriba a una variable, y esa variable colocarla como valor del campo de la plantilla.
Así pues, para crear el nombre del actor, crearemos la entrada y la etiqueta, así como la variable unida a la entrada que se escriba.

En estas líneas tenemos la variable «entry_var_actor» que tomará los datos que escribamos en la «entry_actor» y los convertirá en una variable. Esta variable luego será la que se asigne al campo de texto «Actor» de la plantilla creada al inicio.

Cuando se cree el documento, la plantilla tomará el texto de «entry_var_actor», que es el escrito por el usuario en el cuadro de texto creado mediante entry_actor = ttk.Entry…
3. Menús desplegables
Crearemos cuadros de texto para cada uno de los campos que hayan de rellenarse. Sin embargo, en ocasiones, los campos a rellenar en una resolución tienen un número limitado de posibilidades. Si hablamos de la Jurisdicción Social, la papeleta que se presenta ante el Servicio de Mediación, Arbitraje o Conciliación sólo puede tener dos alternativas, a saber, que se celebró el acto sin efecto, o que se celebró sin avenencia. En ese caso, en vez de optar por un cuadro de entrada, puede optarse por un menú desplegable en el que seleccionar una de esas dos opciones.

Para ello, crearemos un combobox que al pulsarlo desplegará las distintas opciones. En el caso de un modelo de Sentencia por Delito Leve, podría contener la relación de Delitos Leves y vincularse la elección con el cambio de párrafos en distintas partes de la Sentencia, según se trate de un Delito u otro.

Como ya se señaló, lo importante de usar una interfaz gráfica es que todo lo que se haga tenga su reflejo en la plantilla, de ahí que creemos una función para que el comobox arroje un resultado que podamos plasmas en la plantilla. Así pues, creamos la función check_cboxmayorofortuito(event) que determina la creación de la variable «avenecia o efecto» cuyo valor será lo que se señale en la ventana. De tal manera que a la hora de plasmar en el texto de la plantilla el resultado, deberemos asignar al campo «avenencia o efecto» la variable «avenencia o efecto». Dado que Tkinter no nos permite hacer uso de un Diccionario, en virtud del cual el valor de lo mostrado no coincide con el valor de lo plasmado en el texto, es decir, lo mostrado en la interfaz es «Sin avenencia» pero lo que queremos que se escriba en el texto es «sin avenencia» (sin mayúscula inicial), deberemos acudir a una condición para poder adaptarlo y que respete las normas ortográficas.

4. Fechas
Al igual que las entradas y los menús desplegables, en los modelos se suelen incluir también las fechas de distintos eventos, para lo cual utilizaremos un calendario, en vez de una entrada de texto, lo que facilitará su uso.
Para ello, crearemos una entrada de fecha, una DateEntry.

En la DateEntry podremos configurar distintos elementos que serán de gran interés para la automatización posterior, la primera cuestión es el formato de fecha, por defecto, se usará el formato americano, a saber: Mes, Día y Año. Sin embargo, a nosotros nos interesa que se plasme el formato de Día, Mes y Año. Para ello haremos uso de la configuración del patrón de la fecha.
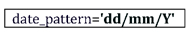
Asimismo, le asignaremos una variable para que, a la hora de plasmar los datos en el modelo, la plantilla tome la fecha concreta.

La representación gráfica de lo programado sería la siguiente:

5. Creación del documento
Una vez creadas cada una de las entradas de los distintos campos que tendremos que rellenar en la plantilla, queda crear el documento. Como se señaló, empleamos para ello la biblioteca docx-mailmerge, que creará un archivo con el texto escrito en el modelo oportuno.
Desde el punto de vista práctico, cada documento que se cree debería ser distinto, por lo que debería ser identificable por distintos elementos, como serían la materia, el número y año del procedimiento e incluso el sentido del fallo. Para ello, crearemos distintas variables que se añadirán al nombre del archivo.

En este caso se ha creado una variable para la materia, otra para el sentido del fallo y otra para concretar en qué supuesto de, Extinción del contrato por voluntad del trabajador, nos encontramos. El resultado por tanto será el siguiente:

Cuando se guarde el archivo el nombre que se muestre tendrá las distintas opciones señaladas, de manera automática sin que el usuario tenga que escribir el nombre.

Una vez creada la interfaz gráfica, el uso del programa de Gestión de Sentencias resulta mucho más útil, al poder rellenar los datos de cada procedimiento, con las alternativas que en cada caso supone para el texto, a saber, si en un modelo de estimación de demanda por recargo de prestaciones tenemos la alternativa de «Caso Fortuito» o «Fuerza Mayor» en un combobox, el texto de toda la fundamentación jurídica variará según se trate de uno u otro caso.

Una vez concluida la parte gráfica, tendremos una aplicación que nos permitirá elegir los distintos modelos y dentro de los mismos rellenar los diferentes campos disponibles y crear los condicionamientos que hagan más útiles y dinámicos los modelos.
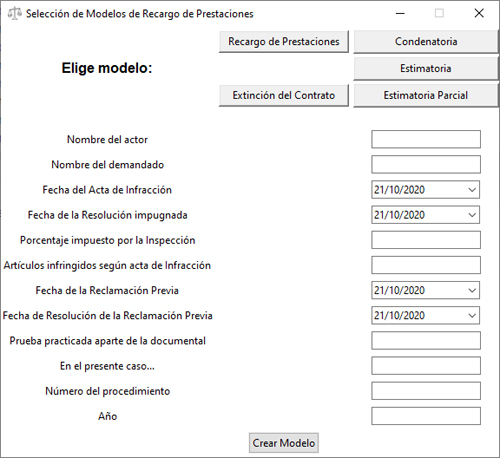
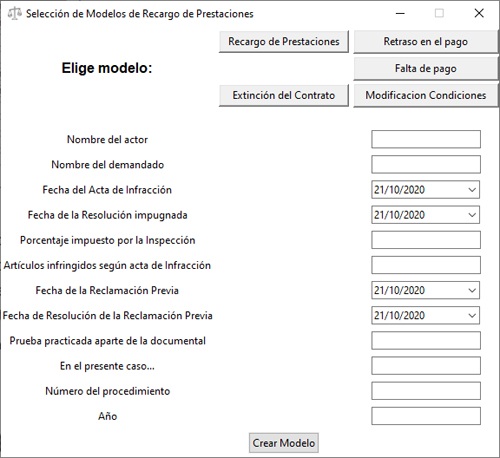
La creación de condiciones y pequeños automatismos ahorrará tiempo a la hora de elegir los modelos y llevar la Resolución al caso concreto, sin embargo, el trabajo de transcripción de cada uno de esos datos: nombres, apellidos, fechas, resultado del SEMAC, actividad de la empresa etc… sigue siendo una tarea repetitiva y sin valor añadido, que resta tiempo a la hora de valorar el caso concreto. De ahí que haya de acudirse al tratamiento de lenguaje natural, como una solución cuya sinergia con una interfaz gráfica de selección de modelos, multiplicará la eficiencia a la hora de dictar resoluciones.
IV. Tratamiento de lenguaje natural
La idea detrás de una Sistema de Gestión de Sentencias es facilitar la labor jurisdiccional y ahorrar tiempo a la hora del dictado de una Resolución. La mayor parte de los datos de una demanda y de una contestación se hayan en papel o recientemente en formato digital. Para la labor de un juez, una demanda en papel no facilita en modo alguno el dictado de la resolución, sin embargo, si están en formato digital esa posibilidad es mayor.
La presentación de los escritos de demanda y contestación cumpliendo con los requisitos exigidos en el Anexo IV.5.6 RD 1065/2015 de 27 de noviembre (LA LEY 18232/2015), entre ellos el reconocimiento óptico de caracteres (en adelante OCR), permite que un Juzgador puede tomar la demanda y copiar y pegar datos de la misma, pero también facilita la posibilidad de automatizar estas tareas.
Esta automatización tiene lugar mediante el uso de herramientas de procesamiento de lenguaje natural. A través de estas herramientas podemos tomar el texto de una demanda, una contestación o un atestado policial (remitido por LexNet en OCR) y trabajar sobre el mismo. De cada texto puede extraerse información relevante a la hora de resolver, información que suele estar recogida en los Sistemas de Gestión Procesal, pero que incluso en aquellos, es introducida manualmente por los funcionarios.
La finalidad de usar herramientas de procesamiento de lenguaje natural es obtener un texto, limpiarlo de «ruido», y examinar los patrones que se repiten en el mismo para poder crear instrucciones, algoritmos, que se cumplan la mayoría de las veces.
Si hablamos de un atestado, la estructura de los mismos suele ser fija, a diferencia de los escritos de demanda y contestación, de tal manera que, si se examina el texto, será fácil obtener un algoritmo que nos permita extraer de un atestado el nombre de las partes (denunciante/denunciado) el delito denunciado, los hechos que se denuncian, la fecha de los mismos etc… Con una demanda ocurrirá igual, deberemos examinar la mayoría de las demandas de los distintos despachos para extraer su estructura, pudiendo crear tantos algoritmos de extracción de texto como despachos haya y hacer depender el algoritmo del nombre del despacho que firme el escrito.
1. Preparación del texto
Para poder llevar a cabo el tratamiento de una demanda, contestación, atestado etc… deberemos instalar las librerías oportunas.

La primera librería será «pdftotext» que nos permitirá convertir en texto plano y tratable el escrito procesal de que se trate. La segunda librería es «nltk», que contiene las herramientas de tratamiento de lenguaje natural (Natural Language ToolKit). La tercera librería es «re», que nos permitirá utilizar Expresiones Regulares (Regex) para poder buscar palabras por patrones.
Mediante el uso de ambas librerías, utilizaremos las distintas funciones que contienen y crearemos las nuestras propias. Para el uso de todas estas funciones, crearemos un archivo aparte, con todas ellas, e importaremos las funciones que necesitemos para el Sistema de Gestión de Sentencias.
Para obtener el texto del «.pdf» enviado por LexNet, crearemos una función que lo automatice, de tal manera que sólo tengamos que seleccionar la demanda, y automáticamente se realicen todas las tareas para convertirlo en texto plano.

Una vez que tenemos el texto, tendremos que limpiarlo y tokenizarlo. Para el tratamiento de los textos, se realizan varios pasos, el primero de ellos es limpiarlo de mayúsculas, signos especiales etc… para que todo el texto sea homogéneo. A continuación se «tokeniza», es decir, el texto pasa de ser una «string», una frase, a ser un conjunto de elemento de una «list», una lista. Una vez tokenizado, convertida cada palabra en un elemento de una lista, esta lista se limpia de «stopwords» o palabras vacías (a saber: a, Acá, Ahí, Ajena/o/s, Al, Algo, Algún/a/o/s, Allá/í, Ambos etc…). Por último, se eliminan los signos de puntuación como la coma y el punto.

Hecho esto ya tenemos un texto definitivo, cuya apariencia es la siguiente:

A partir de este momento, habrá que examinar los textos con los que vayamos a trabajar, para poder entrever los patrones que se dan para poder extraer la información que necesitemos.
2. Creación de patrones
En el caso presente, el Sistema de Gestión de Sentencias lo basamos en la Jurisdicción Social, por lo que habremos de analizar la estructura de las distintas demandas.
En una demanda de Extinción por voluntad del trabajador serán datos de interés a extraer el nombre de las partes, la antigüedad del trabajador, la actividad de la empresa, y el salario día. A diferencia de los atestados, que tiene una estructura homogeneizada, las demandas varían de un despacho a otro, pero podemos extraer reglas comunes a los mismos. Así, de una demanda usual como la siguiente:

Del examen de la primera página podemos apreciar que el nombre del actor suele ir precedido de la palabra «representación» y sucedido de la expresión «mayor de edad». Asimismo, que el nombre del demandado suele ir precedido de la palabra «empresa» y sucedido de la palabra «NIF». En consecuencia, al texto preparado que hemos obtenido previamente, tendremos que aplicarle un algoritmo que extraiga esos datos.
Así pues, creamos una función genérica de búsqueda y extracción de los datos del demandante y demandado.


De forma semejante, programaremos distintas instrucciones para extraer la categoría profesional del actor, su salario, actividad de la empresa etc…

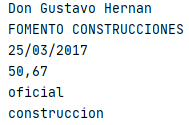
Aplicado este Código sobre el texto de la demanda, nos arrojará en la terminal los datos buscados.

En el caso de las demandas de Recargo de Prestaciones, deberemos crear una función general de búsqueda de fechas, que nos extraiga la fecha interesada en función de las palabras que le precedan o le sucedan. Crearemos una función que buscará el «token» que tenga formato de fecha, más cercano a una palabra concreta.

3. Cálculos
Una vez que hemos obtenido todos los datos de interés de las demandas, en función de los patrones que las mismas suelan cumplir, deberemos trabajar con esos datos.
Una tarea esencial en las demandas de despido o extinción es el cálculo de la indemnización en caso de Sentencias estimatoria. Una vez que hemos extraído los datos de la demanda, podremos crear una función que automáticamente use esos datos de la demanda para calcular la indemnización.

En caso de que se trate de una extinción, la fecha a tener en cuenta sería la del día de creación del modelo, esto es, el día del dictado de la Resolución. Por tanto, la «fecha_despido» sería:

Como se señaló previamente, el formato de la fecha es importante, dado que para poder hacer los cálculos de tiempo habrán de coincidir con el formato elegido, a saber: Día, Mes y Año.
Este tipo de cálculos pueden igualmente aplicarse de forma automática a otro tipo de Modelos, así en el caso de una Sentencia por Delito leve, puede calcularse automáticamente la multa a la que se condena. Así, crearemos una función que tome los datos de la cuota multa y del tiempo de la multa. Dado que en ocasiones la multa puede referirse a meses, si lo que se introduce son números superiores a 3, entenderemos que se refiere a días, si es inferior a 3, entenderemos que se refiere a meses.

V. Sinergia de ambas herramientas
Una vez que, por una parte, hemos creado la interfaz gráfica para la selección de modelos y que, por otra parte, hemos creado la base para extraer de las demandas los datos necesarios para el dictado de una Sentencia, tendremos que integrar ambos programas.
Crear un programa para seleccionar modelos es útil, facilita la búsqueda de los mismos y al rellenar los campos evita olvidos o equivocaciones, al tener todos los elementos variables de una Sentencia.
Sin embargo, un programa de este tipo, sigue requiriendo la necesidad de introducir datos manualmente por el usuario, esto es, seguir realizando tareas que son repetitivas y que no implican una labor de fundamentación y razonamiento. Por ello, integrar en este tipo de programas la extracción de datos de la demanda y su introducción por defecto en el programa, ahorrará tiempo a la hora de crear los modelos.
En definitiva se trata de obtener una sinergia entre una programa que gestione modelos y un algoritmo detrás que introduzca en los mismos los datos que nos interesan y realicen cálculos matemáticos simples.
Para ello, deberemos establecer en algunos de los cuadros de texto de entrada, como valor por defecto el dato que nos interese.
1. Pantalla de Inicio
Si en un principio nuestro Sistema de Gestión de Demandas se limitaba a seleccionar modelos vacíos y rellenarlos, ahora que integraremos herramientas de tratamiento de lenguaje natural, habremos de crear una pantalla de inicio con ambas posibilidades.
Para ello, crearemos en el archivo en el que estábamos trabajando, una ventana inicial, con dos botones, en uno de ellos abriremos una ventana de dialogo para seleccionar la demanda sobre la que vayamos a dictar Sentencia, en el otro iremos directamente a la selección de modelos que estarán vacíos.

El resultado será el siguiente:

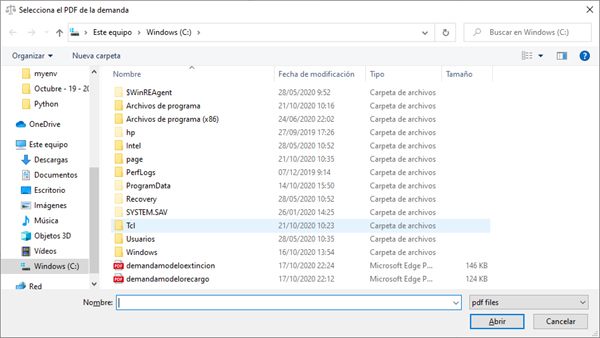
En caso de que se pulse el botón «Selecciona la demanda», se abrirá una ventana de selección.
2. Integración de los datos en el programa
Una vez que seleccionemos la demanda, el código que se mostró en el epígrafe anterior comenzará a extraer todos los datos. Así pues, al extraer el nombre del actor, del demandado etc… deberemos establecer un valor por defecto en los cuadros de entrada de tales campos. Si originalmente, la entrada del nombre del demandado tenía esta configuración:

Ahora que gracias a las herramientas de tratamiento de lenguaje natural tenemos los datos del nombre del demandado, deberemos establecerlo como valor por defecto.

Utilizaremos la función «.insert()» para fijar como datos por defecto los que nos interesen. En el caso de que se trate de una entrada de fecha, usaremos la función «set_date()».

Aplicadas estas funciones a cada entrada concreta, al seleccionar la demanda, obtendremos como resultado los distintos datos rellenados en el modelo.

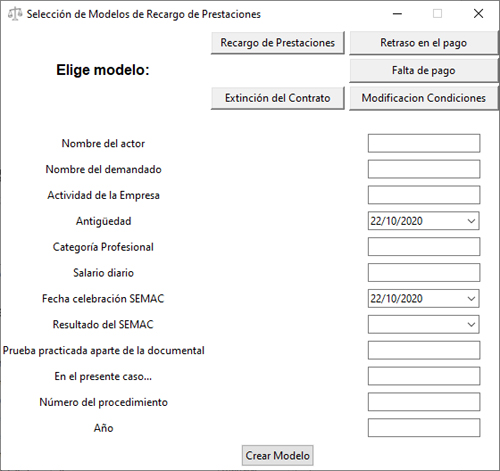
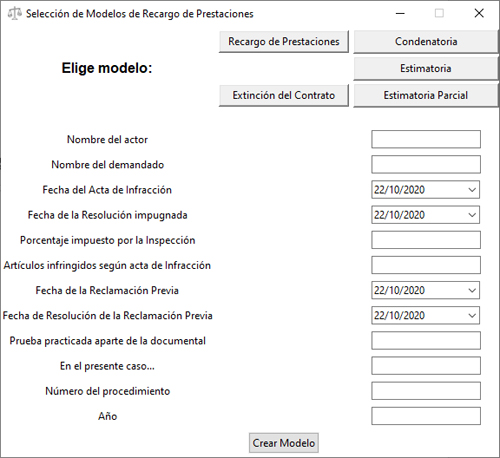
Como se aprecia, mientras que en la opción de Modelo Vacío no hay ningún campo rellenado, si optamos por seleccionar una demanda se rellenan algunos de los campos. Lo mismo sucede con los modelos de Recargo de Prestaciones, en los que se establecen diversas fechas.
En definitiva, lo que estamos haciendo es por una parte organizar el trabajo mediante la estructuración de modelos y plantillas, que nos recordarán que elementos observar y que pasos seguir para la valoración de cada caso concreto, y por otra parte dejamos que sea un algoritmo el que extraiga la información que, importante para el caso, sin embargo, suponga una tarea de mera transcripción. Con ambas herramientas por separado la labor del dictado de una Resolución se facilita, con la unión de ambas, el tiempo que resta, servirá únicamente para la valoración y fundamentación.

VI. Vistas al futuro
La digitalización de la Justicia ha pasado siempre por ser una finalidad administrativa, más que un medio para la facilitación de la labor judicial. La digitalización ha sido asumida por las Administraciones como un elemento a adoptar, para beneficiar el trámite, ahorrar costes operativos etc… sin embargo, la figura del Juzgador siempre ha ocupado un puesto a parte en esa dinámica digitalizadora.
Los Juzgadores a la hora de dictar resoluciones hacemos uso de Procesadores de Textos y Bases de Datos, sin embargo, la necesaria creación de un Procesador de Sentencias, o un Sistema de Gestión de Sentencias, que facilite y automatice determinadas tareas, es una labor que nunca se ha abordado y que reduciría los tiempos de respuesta, en una Justicia cada vez más carente de medios técnicos y personales.
La creación de una Base de Datos de plantillas, lo suficientemente amplia y estructurada, en actualización constante, unido a un programa que descargue y presente de manera sencilla e intuitiva un árbol de plantillas a seleccionar supone un paso adelante en la digitalización de la justicia. Añadiendo a ello herramientas de procesamiento de lenguaje natural, capaz de extraer los datos básicos de un pleito para colocarlos en los campos de texto adecuados de la plantilla, sería otro paso más en lo que ha venido a denominarse la Revolución 4.0. Por último, si a ese programa se añade una Inteligencia Artificial capaz de extraer, del texto de la demanda, contestación, atestado etc… Resoluciones Judiciales en casos similares (mediante un eso adecuado de keywords), los tiempos que ahora se emplean por los Juzgadores a la hora de dictar resoluciones se reducirían drásticamente, y con ello, aumentaría la calidad en el trabajo de Jueces y Magistrados.
Como se ha expuesto a lo largo del presente artículo, a través de la Prueba de Concepto, para la extracción de algunos datos concretos de los escritos procesales, hay que estudiar los patrones a los que responde cada tipo de demanda, cada despacho etc… A los efectos de lograr una efectividad aún mayor, la homogeneización de determinadas partes de una demanda, como podrían ser el encabezado y el hecho primero, facilitaría que el código empleado para extraer dicha información no fuera demasiado complejo, al tiempo que permitiría a los Profesionales una libertad de forma a partir del hecho segundo en adelante de sus escritos. Ello beneficiaría, no sólo a un Sistema de Gestión de Sentencias, sino a los propios Sistemas de Gestión de Procesal que se constituyen como la columna vertebral de la tramitación.
En suma, el Legaltech se está desplegando fuera del ámbito de la Administración de Justicia, e incluso en algunos aspectos en la parte de tramitación, sin embargo, en el universo que rodea a la labor puramente jurídica, seguimos anclados en un Procesador de Textos y en la transcripción manual de datos. La creación y desarrollo de un JugdmentTech, que aborde con soluciones tecnológicas las necesidades de los Juzgadores y facilite determinadas tareas, es un paso necesario para poder hablar de una Justicia eficaz y moderna.
VII. Código Fuente
Disponible en:
https://github.com/xvi82/sistemagestionsentencias