I. Introducción
Estamos en los albores de una nueva era, de un nuevo orden social y económico que tiene sus cimientos en el desarrollo tecnológico. Los avances que se están produciendo en los últimos años son de tal magnitud que ya se habla de generar energía limpia e ilimitada, de la curación de enfermedades letales como el cáncer, de la robotización de gran parte de las tareas que hoy día realizan seres humanos, de la inmersión digital plena en los metaversos, de asentamientos permanentes en otros planetas cercanos a la Tierra, en definitiva, de traspasar fronteras que hasta hace poco parecían infranqueables.
Sin embargo, los elementos disruptores que verdaderamente van a marcar la diferencia en este proceso de transformación económica y social son los sistemas de inteligencia artificial (y en particular, los sistemas de aprendizaje profundo y las redes neuronales) y la computación cuántica.
«Dicen que los sistemas de Inteligencia Artificial van a reformularlo todo: nuestro modelo productivo, nuestro modelo social, nuestra manera de relacionarnos, la forma en que accedemos al conocimiento y hasta nuestra propia individualidad. Proponen que será un fenómeno de una magnitud similar a Internet, pero con un período de adopción muy inferior, de unos pocos años.» (2) .
Si por algo se caracteriza nuestro actual modelo de sociedad es porque los individuos que la conforman están expuestos y demandan diariamente un volumen descomunal de información. La capacidad para acceder a ella, compartirla y especialmente procesarla utilizando sistemas tecnológicos, plantea enormes desafíos y está impulsando la configuración de nuevos dominios jurídicos y derechos que ya forman parte del acervo de uso cotidiano. Este fenómeno, en armonía con la globalización, ha desembocado en lo que algunos autores han denominado como la creación de la sociedad tecnológica electrónica o sociedad red (3) .
Desde una perspectiva jurídica, este cambio tan acelerado de paradigma obliga también a los reguladores y todos los que practican el Derecho a innovar a ese mismo compás a fin de garantizar la protección integral del individuo frente a los riesgos, todavía desconocidos en algunos casos, que pueden derivarse de un mal uso de estas tecnologías. En palabras de FARIA «las transformaciones sociales, políticas, económicas y culturales han venido a exigir una nueva reflexión sobre los problemas centrales de la Teoría General del Derecho, desde el de los modelos jurídicos o el de los métodos hermenéuticos y las fuentes, hasta el de la integración del ordenamiento y las relaciones entre legalidad y legitimidad» (4) .
Uno de los campos en los que esta necesidad de protección del individuo se ha hecho más explícita es en el de la protección de datos personales. Los sistemas de Inteligencia Artificial se nutren de un volumen masivo de datos con la finalidad de establecer patrones entre ellos (5) , lo que ha destapado numerosos conflictos que ponen en riesgo la integridad y seguridad del individuo, tanto en su condición de titular de los datos empleados al efecto como de usuario.
Es una concepción comúnmente extendida que la tecnología es «objetiva» y carece de los sesgos o prejuicios que los humanos puedan tener en base a su ideología, raza, sexo o características personales. Frente a esta postura, en este trabajo trataremos de argumentar que la neutralidad tecnológica no es más que una ilusión que queda desmentida desde la misma instancia del diseño.
Con el propósito de someter a examen esta tesis, analizaremos el empleo de algoritmos en el marco de las relaciones entre las entidades financieras y sus clientes y demostraremos que la tecnología, per se (y no sólo el uso que hacemos de ella (6) ), puede llegar a tener un impacto adverso en los derechos y libertades del individuo y, por tanto, que su diseño debe ser regulado y supervisado por las autoridades, como ponen de manifiesto iniciativas como la Propuesta de Reglamento de Inteligencia Artificial del Parlamento Europeo y del Consejo (7) .
II. Exposición del conflicto: Principios generales del RGPD
Es una realidad innegable que, con la irrupción de la Revolución Digital, los datos personales (8) del individuo-usuario se han convertido en un potencial activo tremendamente útil para las empresas, tanto en el sector financiero como en otros. Debido a la sensibilidad que esta información presenta y las consecuencias que un uso irresponsable de la misma podría tener para los derechos y libertades de los interesados, la protección de esta información de carácter privado y personal y garantizar que su tratamiento es respetuoso con la legalidad habría de ser un objetivo prioritario para las compañías, en particular, para las entidades bancarias, que manejan un volumen ingente de datos personales, incluyendo aquellos de especial sensibilidad, como los que revelan la capacidad de endeudamiento del individuo o con quiénes mantiene relaciones profesionales o íntimas.
La protección de datos se refiere a todas aquellas técnicas, prácticas y métodos que garantizan que el individuo-usuario pueda mantener en todo momento el control sobre sus datos, pudiendo en todo caso acceder a ellos, modificarlos, eliminarlos, saber quién más tiene acceso a los mismos y para qué finalidad se van a destinar. Con ello lo que se pretende es, en palabras del Tribunal Constitucional Español en su sentencia 290/2000, de 30 de noviembre (LA LEY 13/2001) «garantizar a esa persona un poder de control sobre sus datos personales, sobre su uso y destino, con el propósito de impedir su tráfico ilícito y lesivo para la dignidad y derecho del afectado».
Si bien la antigua Directiva 95/46/CE (LA LEY 5793/1995), relativa a la protección de las personas físicas en lo que respeta al tratamiento de datos personales y a la libre circulación de estos datos, ya incorporaba los criterios necesarios para garantizar nuestro derecho a la protección de datos personales en términos muy similares a los actuales, su deficiente transposición en algunos Estados miembros (España como ejemplo de ello (9) ), aconsejaban un modelo nuevo y uniforme. Con ese propósito nació, en el marco de la Primera Agenda Digital (2010-2020) el actual Reglamento (UE) 2016/679 del Parlamento Europeo y del Consejo, de 27 de abril de 2016 (LA LEY 6637/2016), relativo a la protección de las personas físicas en lo que respecta al tratamiento de datos personales y a la libre circulación de estos datos (en adelante, «RGPD»).
El RGPD persigue una doble finalidad. Por un lado, una protección más exhaustiva de los derechos del interesado, es decir, mayores garantías de los derechos recogidos en los tratados europeos de derechos fundamentales (10) y, por otro, dotar al sistema de un marco normativo que acelerase la transformación digital, sobre la base de principios como el de responsabilidad proactiva o de enfoque basado en el riesgo. Para ello, se elaboró un listado de nuevos principios aplicables, entre los cuales, a efectos de este trabajo, destacaremos los siguientes:
- • Licitud, lealtad y transparencia, que se traduce en deberes instrumentales para los fines perseguidos por la norma como el que se recoge en el artículo 12 del RGPD (LA LEY 6637/2016): el deber de informar, en virtud del cual, el responsable del tratamiento debe facilitar a los interesados información concisa, transparente, inteligible y de fácil acceso sobre el tratamiento de sus datos personales.
El empleo de sistemas de Inteligencia Artificial («I.A.»), utilizados actualmente por numerosas entidades financieras para el análisis de créditos, hace prácticamente invisible para el interesado el proceso de elaboración de perfiles. Los usuarios tienen muy distintos niveles de comprensión dependiendo, entre otros factores, de su nivel educativo, sus circunstancias personales y su conocimiento técnico del campo, y puede resultarles difícil entender las complejas técnicas de los procesos de elaboración de perfiles y decisiones automatizadas (11) .
- • Tratamiento y limitación de la finalidad. Una de las principales exigencias que el RGPD impone a los responsables del tratamiento es que la finalidad para la que recaben los datos personales se encuentre correctamente definida, así como que se informe de ella al interesado para que éste pueda conocer el alcance material que tendrá el tratamiento de sus datos personales y esté en disposición, en su caso, de ejercer sus derechos.
Así, cuando en el marco de la comercialización de productos bancarios dirigidos a los interesados se vayan a involucrar técnicas de I.A., se deberá prestar una especial atención a que las finalidades de los tratamientos de las que se les informe coincidan con las finalidades reales para las que se vayan a utilizar sus datos, evitando desviaciones en cuanto al uso de los datos que puedan resultar incompatibles con la finalidad para la que estos fueron recogidos (12) .
- • Minimización de datos. Este principio supone para el responsable de tratamiento aplicar medidas técnicas y organizativas suficientes y efectivas para garantizar que solamente sean objeto de tratamiento aquellos datos que se consideren precisos para los fines específicos del tratamiento limitando a lo necesario el plazo de su accesibilidad.
Cuando se empleen herramientas de I.A., la vigilancia del cumplimiento de esta obligación se debe intensificar, exigiéndose a los responsables del tratamiento una justificación adecuada de la necesidad de recoger y conservar los datos personales que requieran del interesado antes de su recopilación. Por ejemplo, todo indica que, a la hora de otorgar un crédito a un interesado, su lugar de origen o la identidad de los locales que frecuenta para comprar su ropa con su tarjeta de crédito podrían llegar a resultar excesivos.
Debido al uso que se da hoy a los datos personales para la venta de productos y servicios personalizados, las oportunidades que han generado los avances de los sistemas de toma de decisiones automatizadas y la elaboración de perfiles (13) —que permiten ahorros significativos en costes de almacenamiento y conservación— suponen un desafío ante los posibles deseos de las empresas de recabar, en ocasiones, información que va más allá de la estrictamente necesaria para los fines del tratamiento. De igual forma, llegan a conservar estos datos durante un plazo de tiempo más prolongado que el estrictamente necesario para la consecución de dichas finalidades, logrando con ello dotarse de un espectro más amplio en el que basar el aprendizaje de sus algoritmos, algo que puede beneficiar al responsable de los tratamientos, pero que puede llegar a ser tremendamente perjudicial para el interesado.
- • Exactitud. Este principio obliga a que los responsables de tratamiento dispongan medidas adecuadas y eficaces a fin de garantizar que los datos que recaban de los interesados son precisos y se mantienen en todo momento actualizados. En el marco de los tratamientos dirigidos a la elaboración de perfiles, la exactitud deberá estar presente en todas las fases del tratamiento, no solamente en el momento de la recogida del dato, sino también durante la propia creación del perfil y, cuando se utilice el mismo para tomar una decisión sobre el individuo.
Por lo tanto, todas estas fases son cruciales cuando se procede a la elaboración del perfil del interesado, puesto que cualquier error o vicio en la recogida y el análisis de la información puede contaminar todo el proceso y las decisiones adoptadas por el responsable del tratamiento, en particular aquellas que tienen un impacto relevante en la vida del interesado (por ejemplo, si puede o no acceder a un determinado crédito).
1. Sistema de toma de decisiones
Se entiende que las decisiones se adoptan mediante sistemas de I.A. cuando se recurre a procesos en los que estas herramientas son las encargadas de escoger entre varias opciones aplicando parámetros que garantizan que la decisión final es óptima y la que mejor se adapta a las necesidades de la empresa. Las empresas tecnológicas dedicadas a proveer soluciones de I.A. a otras corporaciones, así como aquellas que desarrollan sistemas propios, clasifican sus sistemas según el grado de participación que tenga la solución de I.A. en la toma de la decisión final (14) .
En primer lugar, nos referiremos a las decisiones automatizadas por completo. En ellas, el sistema está en contacto con un volumen masivo de datos y, utilizando los parámetros propios que la empresa haya introducido como método de sesgo, el propio sistema toma decisiones finales, sin ningún tipo de intervención humana en el proceso.
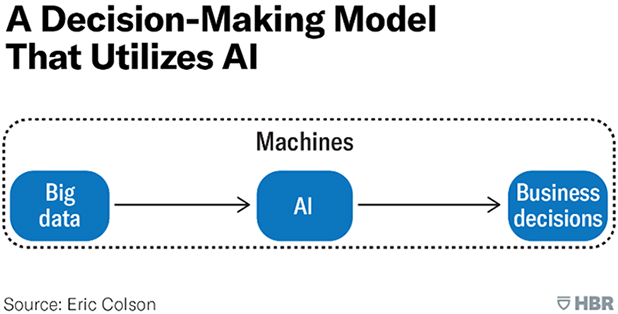
Fuente: What AI-Driven Decision Making Looks Like
A continuación, analizamos una opción que cuenta con una participación menor de la solución de I.A. En este caso, es el sistema el que proporciona a los responsables de la toma de decisiones una o varias alternativas, filtrando todas las opciones disponibles conforme a los criterios previamente configurados por el usuario. En contraste con la decisión anterior, la toma de la decisión final se produce con intervención humana.

Fuente: What AI-Driven Decision Making Looks Like
Por último, y aunque cuenta con menor presencia en el mercado, existe una tercera alternativa, en la que el sistema de I.A. tiene un papel marginal, meramente de apoyo en la toma de decisiones. La solución lleva a cabo un análisis limitado de los datos, pero no ofrece alternativas al responsable de tomar la decisión para que escoja entre ellas. Será el individuo quien tenga la potestad de elegir entre todas las opciones disponibles sin que el sistema haya descartado ninguna previamente.
Actualmente, son muchas las compañías que incorporan algoritmos de I.A. en sus procesos de toma de decisiones, entre ellas, las pertenecientes al sector bancario. Para garantizar los derechos de los interesados a no ser objeto de decisiones adoptadas en procedimientos íntegramente automatizados, se debe incorporar la presencia de un individuo a este proceso, que sirva no solamente para garantizar que se corrigen los factores que introducen inexactitudes en los datos personales, sino, además, para reducir al máximo el potencial riesgo de error (15) .
No obstante, debemos prestar especial atención tanto al momento en el que interviene ese individuo persona física, como al seguimiento que éste pueda realizar sobre el procedimiento seguido por el algoritmo previo a la obtención de los resultados. En este sentido, como expondremos en el punto tercero de este trabajo, en la medida en la que solamente concurra una presencia humana en la última fase del proceso de toma de decisiones y no se pueda acceder al procedimiento seguido por el algoritmo —es decir; encontrándose esta solución de I.A. configurada como una caja negra (16) — será cuestionable que los derechos recogidos en el RGPD estén siendo garantizados.
2. El consentimiento: especial problemática del artículo 13 RGPD
Con la nueva regulación en materia de protección de datos, el consentimiento del interesado es el eje fundamental sobre el que pivota la normativa. Según lo dispuesto por el artículo 4.11 del RGPD (LA LEY 6637/2016), se entenderá por consentimiento «la manifestación de voluntad libre, específica, informada e inequívoca por la cual una persona acepta, mediante una clara acción afirmativa, el tratamiento de sus datos personales». Este artículo se verá intrínsecamente relacionado con las disposiciones del artículo 13 cuando los datos se recaban directamente del interesado, puesto que, a la hora de recabar este consentimiento, la información que el interesado reciba será crucial para determinar la validez del mismo.
El nuevo RGPD establece cuatro requisitos fundamentales para que el consentimiento emitido por el interesado pueda considerarse válido, estableciendo un antes y un después en cuanto a las garantías que la legislación proporcionaba en esta materia. Así, para que se considere válido, el consentimiento debe ser:
- • Libre. El consentimiento habrá de prestarse en un marco de libertad total, lo cual implica control y elección reales por parte del interesado (17) . El legislador presta especial atención a aquellas situaciones en las que se produce un condicionante que obliga al sujeto a consentir en la cesión de sus datos personales, y apunta la importancia de identificar este condicionante para poder determinar si el mismo implica la falta de libertad del usuario en el momento de la cesión.
- • Expreso. No debe quedar lugar a duda de que el interesado está consintiendo el tratamiento de sus datos para la finalidad correspondiente. Debe ser una declaración de voluntad que se ha de expresar de forma afirmativa, clara y mediante una acción positiva. Para obtener un consentimiento expreso es necesario que la información sobre las opciones de las que dispone el interesado sea justa, inteligible y clara y que se obtenga una confirmación específica del interesado. Esta confirmación podrá solicitarse de forma escrita o verbal (por ejemplo, pulsando un botón o proporcionando confirmación verbal) (18) .
- • Inequívoco. En consonancia con el requisito anterior, para poder afirmar que el consentimiento es inequívoco es necesaria una acción claramente afirmativa. Al contrario que en regulaciones de protección de datos anteriores, en el nuevo RGPD se detalla que es necesaria por parte del interesado una acción deliberada e inequívoca de que consiente el tratamiento. Bajo el Reglamento General de Protección de Datos (LA LEY 6637/2016), no cabe el consentimiento tácito ni por silencio, solamente el consentimiento expreso.
- • Específico. La obtención del consentimiento válido va siempre precedida de la determinación de un fin específico, explícito y legítimo para la actividad de tratamiento prevista (19) . Para que el consentimiento sea específico, debe existir una voluntad concreta de aceptar aquellos fines concretos —uno o varios— que el responsable de tratamiento determine y se deben comprender y aceptar cada uno de ellos en concreto y por separado. El responsable de tratamiento deberá proporcionar al interesado en el momento de recabar este consentimiento información sobre los datos que se tratarán para cada finalidad específica.
No obstante, y pese a no reconocerse explícitamente como una de sus principales características según la definición incorporada al artículo 7 del RGPD (LA LEY 6637/2016), se debe contemplar un quinto elemento esencial, pues será la base que sustente el resto de los requisitos ya mencionados a la hora de determinar la validez de este:
- • Informado. Como indica el propio RGPD, cuando se obtengan de un interesado datos personales relativos a él, el responsable del tratamiento, en el momento en que estos se obtengan, tendrá la obligación de facilitarle la información que se halla pautada en el artículo 13, entre la que se encuentran los fines del tratamiento a que se destinan los datos personales y, en su caso, que se van a adoptar decisiones individuales automatizadas en función de estos.
De igual forma, en aquellos procedimientos en los que se empleen técnicas de I.A., se debe concretar en la política de privacidad de la entidad determinada información relativa a la lógica de funcionamiento del algoritmo empleado. En caso de que el interesado no comprenda suficientemente la información ofrecida, y en virtud del principio de responsabilidad proactiva, ésta se puede complementar con una explicación adicional que facilite su entendimiento.
La omisión de detalles tan cruciales respecto de la forma en que se tratan los datos personales del interesado y la ausencia de una alternativa al empleo de los sistemas de I.A. por parte de la entidad conducen hacia un consentimiento invalido, en la medida en que no puede considerarse informado ni libre.
3. Terceras fuentes
Mediante el examen de las políticas de privacidad de diversas entidades financieras, comprobamos que la base legitimadora del tratamiento de la mayor parte de los datos recabados procede del consentimiento del interesado.
Además de los datos proporcionados por el propio individuo-usuario en el marco del procedimiento de concesión de crédito, es común que estas entidades financieras acudan a otros datos obtenidos de fuentes externas a fin de alcanzar una mayor seguridad respecto a la capacidad de endeudamiento del interesado antes de proceder a la concesión del crédito. Esas terceras fuentes pueden provenir tanto de la propia entidad como proveedores de servicio (por ejemplo, las empresas que gestionan los servicios de información crediticia (20) ). La base legitimadora de estos tratamientos será, habitualmente, el consentimiento del interesado.
Los datos procedentes de la propia entidad pueden haber sido recabados en contrataciones de servicios anteriores. Estos datos pueden incluir datos identificativos y de detalle de la actividad profesional o laboral, datos de contacto y datos financieros y socioeconómicos (21) . Un ejemplo de los datos que pueden generarse de los servicios contratados podría ser el siguiente: los extractos de las tarjetas bancarias reflejan en qué tipo de superficies compra el titular, de modo que, si Matilde hiciese su compra semanal en los supermercados Sanchez Romero, se podría deducir que tiene una mayor capacidad económica que si lo hiciese en la cadena de supermercados Lidl.
También, en determinados casos, se puede acceder a determinadas categorías de datos mediante otras fuentes, siendo así posible tratar datos obtenidos de medios tan dispares como redes sociales, aplicaciones de telefonía móvil, navegaciones realizadas en el servicio de banca por internet o los obtenidos de empresas proveedoras de información comercial. No debemos olvidar que las redes sociales y aplicaciones aportan información especialmente sensible, como las ubicaciones desde las que se realizan fotografías y videos, imágenes del propio interesado en el marco de actividades íntimas o sobre el entorno en el que nos desenvolvemos. Incluso información confidencial sobre, por ejemplo, nuestro estado de salud, lo que permite establecer patrones sobre el ejercicio físico que hacemos o sobre nuestros hábitos alimentarios.
Por último, existe un último bloque de datos a los que se puede recurrir cuando se hace uso de sistemas de I.A. Tal y como explica la Autoridad de Protección de Datos en España, la Agencia Española de Protección de Datos («AEPD»), estos sistemas, debido a los procesos de aprendizaje que se analizarán más adelante, funcionan creando datos derivados o inferidos sobre las personas, esto es; datos personales nuevos que no han sido facilitados de forma directa por los propios interesados a ningún responsable.
Las entidades financieras deben cumplir con determinadas obligaciones normativas relativas al denominado crédito responsable y de control de riesgo financiero. Ello supone una continua evaluación de la solvencia financiera de sus clientes mediante el tratamiento de determinados datos personales, tratamiento que arroja como resultado límite de potencial de endeudamiento a cada cliente.
Por este motivo, no es extraño encontrar en numerosas políticas de privacidad de reputadas entidades bancarias (22) determinadas cláusulas en las cuales se especifica que, para el intercambio de flujos de datos en el sistema analítico no aplica el consentimiento del interesado, al considerarse la base legitimadora del tratamiento el interés legítimo de la entidad en cuestión.
Siguiendo el razonamiento de la AEPD, cualquier tratamiento llevado a cabo sobre la base del interés legítimo del responsable del tratamiento en un entorno empresarial será ilícito cuando su única finalidad es la mera obtención de un beneficio económico (o la reducción de una pérdida) (23) .
A este respecto debemos, además, tener en cuenta que en la misma medida en que no es posible amparar un tratamiento en el interés legítimo cuando dicho tratamiento es estrictamente necesario para dar cumplimiento a una solicitud del interesado (en este caso, la base legitimadora del tratamiento es el contrato —art. 6.1 b) del RGPD (LA LEY 6637/2016)—) (24) , es preceptivo en caso de utilizar el interés legítimo como base de cualquier tratamiento llevar a cabo un ejercicio de ponderación de intereses.
III. Funcionamiento de los sistemas de Inteligencia Artificial (IA)
Para tratar de aproximar el auténtico dilema ante el que nos encontramos, debemos comprender de qué forma funcionan este tipo de sistemas, qué tipos podemos encontrar y cuáles son los principales problemas que la falta de transparencia puede acarrear para los interesados.
Decía el famoso escritor Arthur C. Clarke (autor de, entre otras obras célebres, 2001: A Space Odyssey) que cualquier tecnología suficientemente avanzada es indistinguible de la magia (25) . Y ese, precisamente, es el sentimiento que el concepto de I.A. supuso para el conjunto de la sociedad en sus inicios. Aunque la I.A. es un fenómeno que tiene más de medio siglo de historia, no es hasta la década de los 2000 cuando ésta, más allá de un elemento de ciencia ficción, se ha configurado como una opción real a implementar en el mercado, basada, claro está, no en la magia, sino en una herramienta mucho más feroz y sorprendente: el software (26) .
En palabras de FERNANDEZ BEDOYA, la I.A. es el conjunto de teorías y de algoritmos que permiten que las computadoras lleven a cabo tareas que, típicamente, requieren capacidades propias de la inteligencia humana (p. ej., la percepción visual, el reconocimiento de voz o la interpretación de un texto teniendo en cuenta el contexto en el que se produce) y, en ocasiones, mejoran dichas capacidades (27) . Recientemente, el Consejo de la Unión Europea ha dispuesto mediante la propuesta de Ley Reguladora de Inteligencia Artificial («Ley de I.A.») una nueva definición relativa al concepto de Sistema de I.A., exponiéndolo como «el software que se desarrolla empleando una o varias de las técnicas y estrategias […] y que puede, para un conjunto determinado de objetivos definidos por seres humanos, generar información de salida como contenidos, predicciones, recomendaciones o decisiones que influyan en los entornos con los que interactúa.»
La IA presenta la creación de los algoritmos probabilísticos, que incorporan una fuente de discrecionalidad sobre la base de entrenamiento previo
Pero ¿cuál es el gran cambio que representan los sistemas de I.A.? Las más importantes técnicas desarrolladas antes de su aparición se basaban en algoritmos (28) deterministas. Esto quiere decir que la labor principal del algoritmo es ejecutar las mismas decisiones de forma invariable. Teniendo en cuenta las mismas circunstancias, la aplicación arroja una y otra vez la misma solución, sin ningún tipo de discrecionalidad ni margen de apreciación por su parte. Lo que presenta la I.A. es la creación de los llamados algoritmos probabilísticos que, frente al tradicional modelo rígido y automático de toma de decisiones, incorporan una fuente de discrecionalidad sobre la base de entrenamiento previo.
Será tarea del programador (29) arrojar al algoritmo una cantidad considerable de datos, frente a los cuales deberá de tomar una decisión u obtener un resultado. Se enseñará al sistema a distinguir las distintas posibilidades que derivan del análisis de los datos y el propio algoritmo será el encargado de crear patrones entre los datos proporcionados y formar sus propias bases históricas (30) . Por lo tanto, al recibir nuevos datos, el algoritmo utilizará sus patrones para generar un resultado acompañado de una probabilidad de que ocurra (lo que se conocerá como predicción).
1. Sistemas de Inteligencia Artificial: de aprendizaje automático a neuronales
Como hemos visto hasta el momento, un sistema de I.A. se distingue del resto de algoritmos existentes en que, en vez de acatar unas ordenes pre introducidas en su sistema y ejecutarlas de forma idéntica durante toda su vida útil, se trata de modelos que aprenden y crean sus propios patrones de respuesta a medida que se entrenan con datos con los que el programador nutre el sistema, y en que son capaces de mejorar sus resultados conforme van aprendiendo.
De esta forma, se afirma que los sistemas de I.A. no se encuentran programados en sentido estricto, sino que se encuentran entrenados.
A lo largo de las últimas décadas y mediante la rápida evolución que esta disciplina ha ido sufriendo, se han desarrollado numerosos subtipos del concepto de inteligencia artificial, pudiéndose distinguir según su nivel de especialización y el tipo de algoritmos que utilicen (31) .

Fuente: Elaboración propia (inspirada en Deniz Appelbaum)
La modalidad más extendida en este campo es la conocida como de aprendizaje automático, o en inglés Machine learning («M.L.»). Este sistema se basa en la capacidad que el software tiene de aprender de forma autónoma. El método de desarrollo de este tipo de sistemas se rige por tres pilares fundamentales: aprendizaje, entrenamiento y resultados.
El M.L. consigue modelos analíticos de datos automáticamente que permiten hacer predicciones, utilizando algoritmos que hacen posible que los sistemas aprendan de una base de datos, identifiquen patrones y tomen decisiones. En este sentido, podemos afirmar que el algoritmo crea patrones y toma decisiones, sin apenas intervención humana, a partir de su propia experiencia.
Dentro de esta modalidad de I.A. podemos encontrar distintas formas de aprendizaje por parte del algoritmo en función del papel que el programador juegue en el proceso.
- • El aprendizaje supervisado implica un mayor grado de participación del programador. En este sentido, un individuo introduce un numeroso grupo de ejemplos en las bases de datos del algoritmo y se le indica cuales de estos datos debe escoger. Puesto que ya se conocen los resultados, el algoritmo se entrena conociendo que el resultado que emita debe coincidir con el que ya se encuentra determinado. En caso de error por parte del algoritmo, este puede configurarse para que emita una respuesta lo más precisa posible.
- • En el aprendizaje no supervisado, al sistema no se le indica la respuesta que debe reflejar, sino que, basándose en una ingente cantidad de datos a modo de ejemplo, el algoritmo es el encargado de buscar patrones que asocien datos parecidos. Este sistema es especialmente utilizado en el sector financiero a la hora de detectar fraudes y ciberataques.
- • El aprendizaje semi supervisado supone un conjunto de las dos variantes vistas anteriormente. De este modo, se le entregan al sistema una cantidad de datos con y sin respuesta y es el mismo el que debe establecer patrones entre ellos.
- • Por último, en el aprendizaje reforzado, el sistema aprende mediante una dinámica de ensayo-error, lo cual permite conocer qué acciones conllevan una mayor recompensa. Este sistema es comúnmente utilizado en sistemas de navegación y robótica.
A pesar de que el M.L. es posiblemente la modalidad más extendida, no por ello es la más especializada. Ya en el año 1943 Warren McCullonch y Walter Pitts proponían abordar desde un marco puramente teórico en concepto de red neuronal (32) . Posteriormente, en la década de los 50, sería Donald Hebb quien expondría en su obra «Teoría de las redes neuronales artificiales» los procesos de aprendizaje basándose en estas redes que sus predecesores plantearon y que, más tarde, serían la base de lo que hoy en día conocemos como aprendizaje profundo o Deep Learning («D.L.»).
Anteriormente, al definir lo que actualmente se entiende por un sistema de I.A., afirmábamos que la peculiaridad de estos sistemas se basaba en tratar de imitar los mecanismos del aprendizaje humano (33) . Los sistemas de D.L. se caracterizan por utilizar las redes neuronales para desenvolverse entre enormes volúmenes de información.
Según la definición aportada por McKinsey & Company, el D.L. es un tipo de aprendizaje automático que puede procesar una gama más amplia de recursos de datos, requiere menos preprocesamiento de datos por parte de los humanos y a menudo puede producir resultados más precisos que los enfoques tradicionales de aprendizaje automático (aunque requiere una mayor cantidad de datos para hacerlo). En el aprendizaje profundo, las capas interconectadas de calculadoras basadas en software conocidas como «neuronas» forman una red neuronal. La red puede ingerir grandes cantidades de datos de entrada y procesarlos a través de múltiples capas que aprenden características cada vez más complejas de los datos en cada capa. A continuación, la red puede hacer una determinación sobre los datos, aprender si su determinación es correcta y utilizar lo que ha aprendido para hacer determinaciones sobre nuevos datos.
Las redes artificiales tienen el propósito de parecerse en todo lo posible a las redes neuronales provenientes de nuestro cerebro, por lo que en estos sistemas podemos encontrar características similares que no presentaba el M.L. Más allá del aprendizaje mediante un entrenamiento constante, encontramos tolerancia ante los errores —entendida de tal forma que la destrucción de parte de la estructura no impide el funcionamiento del resto del sistema— una adaptación más rápida a los cambios en tiempo real, y una capacidad de organización propia ante la entrada de nuevos datos.
Al igual que ocurre con el cerebro humano, dentro de los procesos de configuración de estas redes neuronales artificiales podemos diferenciar dos fases:
- • Una primera fase de entrenamiento, en la cual, al igual que en el M.L., se escoge un conjunto de datos para realizar el mismo y se procura que el algoritmo aprenda hasta arrojar unos resultados lo más aproximados a los deseados.
- • Una segunda fase de prueba. En ella se utilizarán una segunda categoría de datos, denominados datos de validación, que tendrán el objetivo de introducir un ajuste si es necesario con el fin de poder extrapolar los resultados.
2. Datos de entrenamiento
Tras observar de qué forma funcionan los sistemas de I.A. en todas sus modalidades, comprobamos que los datos de los que se nutre el sistema a lo largo de todo su proceso de entrenamiento son la base fundamental de su posterior toma de decisiones (34) .
Los usuarios, como ya se ha expuesto, generamos datos de forma constante y masiva a partir de nuestras interacciones con medios electrónicos, ya sea directa o indirectamente. Estos datos, a su vez, son canalizados para extraer información que pueda resultar útil a cada negocio. El tratamiento de estas cantidades masivas de datos es lo que se conoce como Big Data («B.D.») (35) . Mediante la recogida, almacenamiento y procesamiento de estos datos, se facilita enormemente la labor de análisis que lleva a cabo el sistema de I.A., ya que proporcionan una enorme base de entrenamiento para la mejora del sistema.
Para que los resultados arrojados por el algoritmo sean lo más concisos posible, los datos de entrenamiento deberán ser variados, extensos y preferiblemente abundantes. Es decir, para que los resultados se aproximen al resultado deseado, el espacio muestral debe ser variado y contemplar todas las alternativas posibles sin discriminar ninguna.
Los datos utilizados en esta clase de entrenamientos pueden provenir de diversas fuentes. En la actualidad son muchos los bancos que están empezando a introducir para configurar sus sistemas de I.A. los llamados «datos sintéticos». Los datos sintéticos se basan en información creada artificialmente que no representa eventos u objetos del mundo real. Normalmente, se emplean en dos situaciones: cuando los modelos recurren a información personal o sensible en la fase de entrenamiento y cuando es preciso incrementar el volumen de datos de calidad, dado que no hay suficientes observaciones (36) .
Sin embargo, este supuesto está muy lejos de representar la realidad en la mayor parte de las empresas del sector financiero, pues generalmente son los datos obtenidos de los propios clientes los que configurarán la base del algoritmo. En el caso que ahora nos ocupa, se informaba a D.ª Matilde de que los datos que se utilizarían de base para tomar la decisión sobre su crédito provendrían de los datos cedidos por ella misma, así como otros recabados por la entidad con base en el interés legítimo. Estos datos, como ya hemos visto, no solamente se basaban en la relación personal de la cliente con NovoBank, sino que tenían en cuenta otros detalles de origen socioeconómico y personal-demográfico.
Como apuntábamos al inicio de este trabajo, dos principios fundamentales que recoge el nuevo RGPD y que serán esenciales a la hora de tratar datos personales son los de minimización de datos y de limitación de la finalidad. Frente a una solución de I.A. que basa su eficiencia en la optimización de sus resultados —resultados que sólo pueden adquirirse mediante un aprendizaje basado en el mayor volumen de datos posible— la tentación por parte de las empresas de recabar un volumen innecesario de datos o de conservar estos mismos más tiempo del necesario puede ser irresistible.
3. Del sesgo cognitivo al sesgo algorítmico
Como hemos resumido hasta el momento, un sistema de I.A. trata de simular en algunas de sus vertientes, los procesos mentales que podría llevar a cabo un ser humano. Es por esto por lo que no podemos analizar los sesgos algorítmicos sin comprender su origen: los sesgos cognitivos del pensamiento humano. A su vez, el concepto de sesgo cognitivo no puede comprenderse sin el esencial trasfondo de la heurística.
El cerebro se ve expuesto a ingentes cantidades de información de forma constante, por lo que se ve obligado a buscar vías para realizar su trabajo de procesamiento de forma rápida y eficiente. Es de esta evolución de la que surge la heurística, definida como aquellas soluciones eficientes a problemas de juicio y elección cuando el tiempo, el conocimiento y las capacidades de procesamiento de la información se encuentran limitados (37) .
Sin embargo, este sistema también presenta sus carencias, puesto que al reducir la dificultad de las tareas a las que se enfrenta la mente a principios heurísticos mucho más simples y condicionados por la experiencia previa, se corre el riesgo de repetir patrones de forma sistemática y aleatoria en la que se reproduzca un error una y otra vez, y es este proceso el que se conoce como sesgo (o bias en inglés).
Conforme a la definición facilitada por los psicólogos israelíes Kahneman y Tversky en 1972, un sesgo cognitivo es una interpretación errónea sistemática de la información disponible que ejerce influencia en la manera de procesar los pensamientos, emitir juicios y tomar decisiones. Un ejemplo de esto podría ser el siguiente: va usted caminando por una calle buscando un lugar para comer y se encuentra con dos restaurantes para usted desconocidos, de ambiente y carta muy similar. El primero de ellos se encuentra cuasi repleto de gente y el segundo está casi vacío. Usted se decide por el que se encuentra lleno de gente. ¿Por qué? Porque su experiencia, gustos, miedos o personalidad le empujan a pensar que el más transitado será mejor, al ser escogido por un mayor volumen de gente. De esta forma se configura el más relevante de los tipos clásicos de sesgos no siendo, sin embargo, el único.
El individuo no se ve aisladamente afectado por aquellos sesgos cognitivos individuales que se forman a raíz de sus propias circunstancias y experiencias, sino que se encuentra igualmente expuesto a aquellos que las estructuras sociales que lo rodean inculcan de forma inconsciente en él. El llamado sesgo cultural deriva de la sociedad de la que formamos parte, del lenguaje que hablamos o de las enseñanzas que hemos recibido a lo largo de nuestra vida. Pensar que una persona de etnia calé es más propensa a cometer un delito de hurto que una persona asiática podría ser un ejemplo de esto.
Por último, el llamado sesgo estadístico procede de cómo obtenemos los datos, de errores de medida o similares. Si quisiéramos estudiar la afinidad de la población por un candidato político y solamente tomásemos muestras de aquellas áreas geográficas de votantes que sienten afinidad por la ideología que representa, los resultados no podrían arrojar una perspectiva realista.
Pese a que los algoritmos, como técnicas de procesamiento, carecen de sensibilidad, criterio y orientación natural y pueden acertar o errar —ya que sus aciertos no se guían por la certeza de la veracidad comprobada, sino por aquella obtenida por la incidencia estadística (38) — no debemos olvidar que el núcleo de cualquier sistema de I.A. es el programador que la configura, así como los datos de los que se nutre en su aprendizaje. En opinión de O’NEIL, los modelos no son sino opiniones integradas en matemáticas (39) .
En el caso de que los datos base de los cuales el algoritmo debe aprender y que el programador pone a su disposición se encuentren sesgados de algún modo —por ejemplo, si se introducen en el algoritmo datos de sonido para que aprenda a distinguir voces y solamente se entrena con voces agudas, llegando a no reconocer las graves— los patrones que se creen estarán contaminados, y la conclusión lógica que se alcanzará dictará que los resultados que arrojará el sistema se encontrarán igualmente sesgados. Esto lo que conocemos como sesgo algorítmico.
4. Especial problemática del artículo 22 del RGPD
Como se ha relatado hasta este punto, los datos personales de los usuarios se han transformado con el tiempo en uno de los principales activos de las empresas. Un estudio elaborado por IDC titulado «Worldwide Big Data Technology and Services, 2022-2027» estima el valor de la economía del dato en los 90 billones de euros en 2022, pudiendo ascender hasta los 180 billones en 2026.
Mediante diversos sistemas de toma de decisiones individuales automatizadas, entre las que destaca la elaboración de perfiles o en inglés profiling (40) , las empresas del sector financiero pueden conocer de forma más cercana las necesidades del cliente y adaptarse mejor a la hora no solamente de ofrecer ciertos servicios y experiencias personalizadas sino también de saber qué créditos se adaptan a sus necesidades y cuáles no.
Los datos personales de los usuarios se han transformado con el tiempo en uno de los principales activos de las empresas
Ante los perjuicios que un mal uso de estos datos pudiera causar en los interesados, el RGPD ha previsto la necesidad de reconocer nuevos derechos a los individuos-usuarios, de forma que sus datos no queden expuestos a la vorágine algorítmica que podría causar una máquina sin supervisión humana.
El artículo 22 del RGPD (LA LEY 6637/2016) reconoce el derecho de todo interesado a no ser objeto de una decisión individual basada únicamente en el tratamiento automatizado que produzca efectos jurídicos en él o le afecte significativamente de modo similar (41) .
Sin embargo, el alcance de este derecho puede verse acotado ante la concurrencia de determinadas circunstancias. El consentimiento explícito del interesado, la celebración o la ejecución de un contrato entre el interesado y un responsable del tratamiento o si este tratamiento automatizado está autorizado por el derecho de la Unión Europea («UE») o de los Estados miembros son los límites contemplados por la propia normativa.
Es importante destacar que las mencionadas excepciones no se basarán nunca en las categorías especiales de datos personales recogidas en el artículo 9 (42) . Las únicas excepciones a esta premisa son:
- • El interesado dio su consentimiento explícito para el tratamiento de dichos datos personales.
- • El tratamiento es necesario por razones de un interés público esencial, sobre la base del derecho de la UE o de los Estados miembros.
A este respecto, el Grupo de Trabajo sobre protección de datos del artículo 29 («GT29») ha llevado a cabo un análisis sobre el contenido de este artículo, que plasmó en sus llamadas Directrices sobre decisiones individuales automatizadas y elaboración de perfiles a los efectos del Reglamento 2016/679 (LA LEY 6637/2016), de fecha 3 de octubre de 2017.
La perspectiva aportada por el GT29 supondrá una garantía adicional frente a los interesados, pues la consideración que este hace del artículo 22 como una forma de tratamiento y no solamente como un mero derecho enfatizará que existe una prohibición general para realizar este tipo de tratamientos, que sólo cabrán de forma excepcional cuando concurran alguna de las excepciones anteriormente citadas (43) .
Por lo tanto, tal y como anunciamos al inicio de este trabajo, se ha de prestar especial atención a aquellos supuestos en los que la intervención humana solamente se dé en la fase final del proceso de toma de decisiones, y la resolución utilice como base los resultados obtenidos por el algoritmo de I.A. en un procedimiento invisible al sujeto.
El hecho de que se proporcione a los interesados información adecuada sobre el sistema de toma de decisiones cobrará una importancia esencial, puesto que en caso de conocer y comprender que la intervención humana solamente se dará al final del proceso, tomando como base unos resultados obtenidos de procedimientos opacos absolutamente automatizados, el individuo-usuario debe tener la opción de acogerse al derecho que este artículo 22 garantiza, por los motivos que se expondrán a continuación.
5. Derecho a la intervención humana
En el apartado segundo de este trabajo se han nombrado los distintos modelos de sistemas de I.A. según el grado de participación que tenga el algoritmo en la toma de la decisión final. Entre ellos, exponíamos el modelo de «método combinado», en el cual es el propio algoritmo quien proporciona a los responsables de la toma de decisiones una o varias alternativas de respuesta tras haber analizado los datos introducidos conforme a unos parámetros previamente establecidos. Una vez llevado a cabo el proceso de análisis, la decisión final sobre la concesión del crédito la tomará un individuo, persona física.
Actualmente, son muchas las empresas presentes en el mercado que tienen implantado este tipo de modelo en sus procesos internos. En este sentido, son cada vez más abundantes las entidades de crédito que incorporan estos sistemas para resolver sobre las solicitudes de concesión de crédito de sus clientes. Mediante el uso de esta técnica, justifican cumplir de forma voluntaria y directa con el derecho de los interesados a no ser sometidos a decisiones individuales puramente automatizadas.
En el propio RGPD se establece que la razón de esta garantía de intervención humana se sustenta en la obligación del responsable del tratamiento de adoptar medidas técnicas y organizativas apropiadas para garantizar que se corrigen los factores que introducen inexactitudes en los datos personales y se reduce al máximo el riesgo de error, y se impidan efectos discriminatorios en las personas físicas por posibles motivos de raza, origen étnico, sexo, orientación sexual u otras que den lugar a medidas que produzcan tal efecto.
Sin embargo, en el supuesto en el que los datos utilizados por el algoritmo para resolver sobre la situación concreta queden fuera del alcance del individuo encargado de la toma de la decisión final, no existirá una auténtica transparencia en el proceso.
La pregunta que la situación suscita es si realmente podemos considerar esta mínima intervención humana como un medio que garantice los derechos de los interesados. Si al encargado de la toma de decisiones en cuestión solamente se le ofrece una estadística que refleja un nivel de riesgo elevado respecto de la devolución de un crédito y no se conocen los motivos por los que el algoritmo ha emitido este resultado, el objetivo que debe cumplir la intervención humana en el proceso —actuar como medida técnica que garantice que se reduce el riesgo de error basado en factores discriminatorios— no se estaría alcanzando.
Anteriormente se ha expuesto en este trabajo lo que representa un sesgo. Se ha hablado de los sesgos cognitivos hasta llegar al origen y significado de los sesgos algorítmicos. En este supuesto, encontramos presente un nuevo tipo de sesgo altamente preocupante que se produce en los humanos en los procesos interactivos con herramientas de I.A., que es el sesgo en la interpretación de los resultados. Este sesgo humano consiste en aceptar, sin espíritu crítico, los resultados de una I.A. como ciertos e inamovibles, asumiendo un «principio de autoridad» derivado de las expectativas creadas por dichos sistemas (44) .
Por ello, podemos concluir que, al basarse los resultados obtenidos en los patrones creados por un sistema de caja negra, se está confiando de modo ciego en que el algoritmo no solamente aplique criterios estadísticos y relacionales deducidos de patrones creados mediante el aprendizaje, sino además en que tenga la intuición y el sentido de la justicia propios del ser humano para tomar una decisión justa en cada situación concreta.
IV. Nuevos retos y oportunidades: vías para lograr una solución
Los problemas relacionados con los sesgos que presenta la I.A. ponen en jaque los derechos de los interesados pudiendo, incluso, provocar situaciones discriminatorias cuando las decisiones adoptadas se basan en determinados datos personales no aportados por el usuario, sino generados a base de patrones creados por el propio algoritmo (45) .
Ante la creciente y notable inseguridad que el imparable avance de estas tecnologías supone para los derechos fundamentales del individuo-usuario, sin que el escudo del Derecho haya conseguido procurar hasta el momento alternativas efectivas para su protección, en esta sección se plantea un sistema de control estructurado en tres pilares sólidos: regulación de los datos empleados, regulación del tipo de algoritmo que se emplee y auditado de los resultados finales (46) .
Como hemos visto anteriormente, los datos utilizados para llevar a cabo el entrenamiento del algoritmo muchas veces pueden ser el origen del problema. La ausencia de práctica con determinados perfiles durante la fase de entrenamiento o el uso de bases de datos históricas que contengan un sesgo arraigado pueden predeterminar unos resultados erróneos en las conclusiones del algoritmo. Este fue, por ejemplo, el caso de Richard Lee, ciudadano neozelandés de origen asiático al que se negó expedición de un pasaporte porque al aportar una foto para su pasaporte neozelandés, el sistema la rechazó al determinar que aparecía con los ojos cerrados (47) . Pese a que en la UE ya se han comenzado a tomar medidas en el sentido de la regulación de los datos que se emplean en los procesos de configuración de los algoritmos, el problema todavía no ha sido erradicado, debiendo incidirse de forma directa en la ética desde el diseño del algoritmo y la recogida del dato, lo cual analizaremos en profundidad en el apartado siguiente.
En segundo lugar, el problema puede encontrarse en la configuración del propio algoritmo. Entre los diversos modelos de sistemas de I.A. que podemos encontrar, es en la actualidad común que este se encuentre configurado como una caja negra, como vemos en el supuesto práctico que nos ocupa. Como se ha expuesto, una caja negra produce un resultado sin explicar de qué forma ni en qué detalles se ha basado para tomarla. Por lo tanto, se crea un conflicto entre la corrección estadística y la justicia individual que corresponde a la persona sobre la que se resuelve en un sentido desfavorable. Existe una falta de transparencia en esta tecnología. Un modelo de caja negra significa no humano. Ni siquiera los programadores y administradores de la máquina o el algoritmo saben o entienden cómo se llegó al resultado (48) . En la medida en la que no se puedan identificar estos procesos, tomar decisiones que afecten a la vida diaria de las personas de forma directa (como la concesión de un crédito o el acceso a un puesto de trabajo) puede suponer un error. Es un deber de los legisladores, investigadores y programadores el colaborar conjuntamente en la investigación de nuevos algoritmos que funcionen como cajas blancas y garanticen la trasparencia.
Por último, se ha de garantizar la comprobación sistemática de los resultados obtenidos, ya que siempre ha sido la principal barrera de control de los sistemas de software. Estas labores de auditoría pueden llevarse a cabo bien de forma interna, por programadores y otro personal familiarizado con el sistema de I.A. y su uso, o bien de forma externa por organizaciones de protección de los individuos-usuarios o empresas dedicadas a estos asuntos en específico y sean contratadas para tal fin.
V. Implicaciones éticas del supuesto
Como se ha expuesto al inicio de este trabajo, vivimos en una era en la que los datos representan el principal activo de las empresas tanto públicas como privadas. Toda esta información, que se recaba de forma masiva motivada por diferentes finalidades, es analizada por unos algoritmos que conocen más del individuo, de sus deseos, necesidades y particularidades, de lo que podrían hacerlo por sí mismos. Sin embargo, lejos de la utopía que esta situación pudiera aparentar ser, los riesgos que entraña la visión fría, amoral y automática de un sistema de I.A. suponen severas amenazas a los derechos de los ciudadanos, mucho más vejatorias e intrusivas que las que cualquier humano podría causar a tal número de interesados al mismo tiempo.
La idea de que la tecnología es inocua, objetiva y carece de los sesgos o prejuicios que los humanos podemos tener por nuestra forma de pensar o por nuestras circunstancias personales decae a gran velocidad en pos de la realidad oculta tras la configuración de estos programas. Detrás de cualquier sistema de I.A. encontraremos un trabajo humano de programación, y la experiencia dicta que es relativamente común es que los sesgos del creador pasan también a formar parte de la obra, ya sea de forma inocente o intencionada. Esta circunstancia sumada a las propias limitaciones técnicas del diseño del sistema, así como a la interpretación que pueda llevar el mismo de los datos que se insertan para su aprendizaje, incrementan las formas de discriminación de forma automática y exponencial en todos los resultados que produzca el algoritmo.
En palabras de FAILERO, en un contexto en el que hemos redefinido la esencia técnica y jurídica misma de los algoritmos que usan las aplicaciones e implementaciones de estas técnicas, nos encontramos reducidos simplemente a ser la carne de la cual se alimentan. En nuestras sociedades dataístas y algoritmocentristas, en las que todo es parametrizado, hipervigilado y controlado, somos lo que nuestra identidad digital refleja que somos (49) .
A día de hoy son muchos los escándalos que involucran a un algoritmo —presuntamente sin preferencias ni gustos personales— en situaciones comprometidas relacionadas con la discriminación de determinados individuos por razones raciales y de género, entre otras. Tal grado de atención ha reclamado este problema que ha llegado incluso a nuestras pantallas a través de la plataforma Netflix, mediante el documental «Sesgo Codificado», en el que la protagonista, estudiante del Instituto de Tecnología de Massachusetts (MIT) de raza negra, explica cómo un sistema de I.A. basado en el reconocimiento facial no fue capaz de detectar su cara, al no haber sido entrenado este algoritmo con suficientes rostros de raza negra. Tras detectar este problema y exponerlo en internet, fueron muchas las voces que se alzaron para exponer situaciones muy similares. Ante este problema, se creó en los EE. UU. la llamada «Liga de la Justicia Algorítmica». Pese a que este problema se ha dado igualmente en Europa, no conocemos de la creación de grupos que luchen de forma activa por este cometido. Sin embargo, desde las Instituciones Europeas comienzan a surgir iniciativas legislativas que buscan terminar con un fenómeno existente y que afecta cada día a individuos dentro de nuestras fronteras.
Existen propuestas de normas a nivel europeo para cubrir la responsabilidad derivada de los daños que los fallos en un sistema de IA puedan causar a los ciudadanos y usuarios
Los algoritmos pueden causar y causan daños a los ciudadanos y usuarios. Tanto es así que ya existen propuestas de normas a nivel europeo para cubrir la responsabilidad derivada de los daños que los fallos en un sistema de I.A. puedan causar. Por su parte, la posición común del Consejo de la UE sobre la anteriormente mencionada Ley de I.A., consta de un enfoque basado en estos riesgos y establece un marco jurídico horizontal y uniforme para la I.A., encaminado a prevenir daños y perjuicios, y para ello, garantiza que los sistemas de I.A. cumplan con unos requisitos de seguridad elevados (50) . Por su parte, la Directiva que regulará la Responsabilidad por los daños de Inteligencia Artificial («Directiva RIA») vela para que, en caso de que el riesgo se materialice en un daño o perjuicio, la indemnización sea efectiva y realista (51) .
El Grupo Independiente de Expertos por una Inteligencia Artificial Fiable, en su obra Directrices éticas para una I.A. fiable (52) , expone que la fiabilidad de I.A. se apoya en tres componentes que deben satisfacerse a lo largo de todo el ciclo de vida del sistema: a) la licitud, entendida como que la I.A. debe cumplir todas las leyes y reglamentos aplicables; b) la ética, de modo que se garantice el respeto de los valores éticos; y, por último c) la de que la I.A. debe ser robusta, tanto desde el punto de vista técnico como social, puesto que este tipo de sistemas, incluso si las intenciones son buenas, pueden provocar daños accidentales (53) .
Estos principios, que deben integrar cualquier sistema de I.A. —tanto propio como de terceras empresas—, deben encontrarse integrados desde las primeras fases del desarrollo del proyecto, en un enfoque «ético por diseño» (54) . Esto significa también que un estudio de viabilidad realizado al inicio de un proyecto de desarrollo de I.A. debería incluir un apartado específico en relación con la conformidad de este sistema con determinados principios éticos, rechazando de facto aquellas soluciones que no cumplan con los mismos.
En palabras de BENÍTEZ EYZAGUIRRE, un algoritmo que procure garantizar la transparencia de los datos que utiliza debe, además de programarse para este propósito, nutrirse de datos abiertos (55) que se encuentren al alcance del público, y que el mismo algoritmo, a su vez, haya sido creado con código abierto, de modo que pueda ser auditable y alterable (56) . Lo que se pretende conseguir con esta corriente es que el algoritmo resulte transparente y permita auditorías sistemáticas sobre sus cambios u operaciones (57) .
Sin embargo, ha quedado demostrado que tal y como se encuentra planteado actualmente el panorama social y legislativo que rodea las técnicas de I.A., las consecuencias de estos sistemas no pueden ser inocuas.
Por lo tanto, ante la cuestión que subyace y conforma el trasfondo de este trabajo, que se traduce en averiguar si el sesgo algorítmico es evitable, la respuesta debe ser negativa (58) , o al menos no en el actual estado de la técnica. Supone un error sin retorno el abandonar decisiones cruciales relativas al ejercicio de derechos fundamentales, como la toma de decisiones administrativas o judiciales (59) , la videovigilancia o el reconocimiento facial en base a datos biométricos (60) entre otras que, aunque no relacionadas con el ejercicio de determinados derechos, afectan de forma negativa a ámbitos principales de la vida del ciudadano, tales como el financiero, el educativo o el ámbito de la salud (61) en manos de estos algoritmos.
La mencionada transparencia que se predica desde las instituciones en todos los ámbitos de la I.A. tampoco resulta efectiva, pues subsiste desde un primer momento la ya patente desconfianza por parte del titular del dato sobre el tratamiento que pueda estar recibiendo sin que previamente se haya informado al titular. Del mismo modo, si no se llevan a cabo los necesarios estudios de impacto en materia de protección de datos personales —auditorías en materia de seguridad de datos y de seguridad de la información, entre otros— en búsqueda de posibles vulnerabilidades, las empresas se encuentran a ciegas en cuanto a los derechos relativos no solo a la privacidad, sino también a la ciberseguridad de los datos (62) .
VI. Conclusiones
A lo largo de este trabajo se ha tratado de plasmar la problemática existente en el panorama actual derivada del uso de sistemas de I.A. de caja negra, tan extendidos en distintos ámbitos dentro del mundo de la empresa, y su impacto, en particular, sobre el derecho fundamental a la protección de datos del individuo-usuario.
Después de un breve análisis de los principios generales de que plantea el Reglamento General de Protección de Datos (LA LEY 6637/2016), nos hemos adentrado en los sistemas utilizados por algunas de las empresas del sector bancario para la toma de decisiones de concesión de créditos, tomando en consideración los datos utilizados y las fuentes propias y ajenas de las que éstos proceden.
Respecto de los datos obtenidos a través de terceras fuentes, hemos observado la facilidad con la que las empresas utilizan de forma ambigua la base intereses legítimos. Como hemos expuesto, no puede resultar de aplicación el interés legítimo alegado, ya que no resulta factible con el principio de licitud del tratamiento que una entidad recabe datos personales para poder prestar un servicio solicitado por el cliente y que posteriormente los emplee para finalidades que resulten incompatibles con aquella, ya que a cada finalidad le ha de corresponder una base legitimadora específica.
A continuación, hemos examinado el funcionamiento de los sistemas de I.A. mediante un aprendizaje menor o mayormente supervisado, así como los distintos tipos de sistemas de I.A. que existen en la actualidad, desde los más sencillos hasta modelos más complejos basados en redes neuronales. Se ha expuesto de qué forma se entrenan estos sistemas mediante datos y cómo la ausencia o introducción sesgada de información en los mismos puede provocar un sesgo en sus resultados arrojados por un algoritmo erróneamente entrenado.
Se ha hecho un recorrido asimismo de las garantías previstas en el RGPD, que se traducen en el derecho a no ser objeto de una decisión individual puramente automatizada y a la intervención humana en tales procesos. En el caso aplicado a los métodos combinados de I.A. en los cuales la intervención humana solamente se garantiza en la fase final del procedimiento de toma de decisiones, siendo invisible al encargado de la toma de la decisión final el procedimiento seguido por el algoritmo, hemos constatado el incumplimiento flagrante del artículo 22 del RGPD (LA LEY 6637/2016). Encontramos justificación en el hecho de que esta medida técnica adoptada para garantizar la participación de un ser humano en el proceso, no puede considerarse siquiera como tal intervención humana, en la medida en que no es eficaz para mitigar el riesgo de posibles errores derivados del uso de este tipo de algoritmos. Con estos argumentos se ha desmontado suficientemente la creencia de que estas garantías se encuentren correctamente definidas o sean suficientes tal y como está configurado su sistema actualmente.
Posteriormente se ha tratado de aportar luz a un problema aún sin solución, examinando tres perspectivas diferentes de mejora que se han de combinar para garantizar un resultado que proteja de forma efectiva al usuario. Finalmente, se han contemplado las implicaciones éticas que presenta este supuesto, demostrando qué, aunque menos conocido a nivel popular, se trata de un problema real, preocupante y ante el que se debe actuar de forma contundente y suficiente.
La conclusión de todo lo aquí expuesto no es sino una señal de alerta, puesto que son muchos los obstáculos que deberá superar todavía el Derecho aplicado a las nuevas tecnologías para alcanzar el grado de protección del individuo que los derechos fundamentales exigen. Como anteriormente apuntábamos, la Revolución Digital es imparable y el derecho no puede quedarse atrás, dejando desamparados a los interesados ante la vorágine digital que ya se cierne inevitablemente sobre nosotros. No se trata de un problema meramente teórico que pueda resolver la moral individual, es el momento de que el legislador actúe y aplique los preceptos morales que nos rigen como sociedad, adaptándolos a esta novedosa realidad en la que vivimos y que nos proteja ante los desafíos que plantea la proliferación de estos nuevos jugadores, carentes de raciocinio y del sentido de la justicia que caracteriza al ser humano moderno, y que ya se encuentran y empiezan a dominar el tablero de juego.
VII. Bibliografía
- — Agencia Española de Protección de Datos en su Guía de Adecuación al RGPD de tratamientos que incorporan Inteligencia Artificial.
- — Agencia Española de Protección de Datos (2020) Adecuación al RGPD de tratamientos que incorporan Inteligencia Artificial. Una introducción.
- — BBVA innovación (2022) Datos sintéticos: así puede entrenarse la inteligencia artificial sin usar información de personas reales.
- — BALMACEDA, T.; SCHLEIDER, T.; PEDACE, K., «Bajo observación inteligencia artificial, reconocimiento facial y sesgos» en Ediciones Universidad de Salamanca Vol. 10, No. 2 (2021), 2.ª Época, 21-43.
- — BENÍTEZ EYZAGUIRRE, L., «Ética y transparencia para la detección de sesgos algorítmicos de Género» en Estudios sobre el Mensaje Periodístico Vol. 25 Núm. 3, enero de 2019, pp. 1307-1320.
- — BONSIGNORE FOURQUET, D., «Sobre Inteligencia Artificial, decisiones judiciales y vacíos de argumentación» en Teoría & Derecho. Revista De Pensamiento jurídico, Vol. 29, junio de 2021, 248-277
- — CALVO SALANOVA J.L., «Sistemas de Inteligencia Artificial» en Huella Digital: ¿Servidumbre o servicio? 1ª ed., Valencia (Tirant humanidades), 2022, pp. 24 a 27
- — CASTELLS OLIVAN, M., «Materiales para una teoría preliminar de la sociedad red», en Revista de Educación, núm. extraordinario (2001), pp. 41 a 58.
- — CERÓN, R. «Inteligencia artificial hoy: datos, entrenamiento e infrerencias» en IBM Systems Blog para Latinoamérica (2019), pp. 1 a 3.
- — COLSON, E., «What AI-Driven Decision Making Looks Like» en Harvard Business Review, julio de 2019, p. 2.
- — Consejo General de la Abogacía Europea (2020), Respuesta de CCBE a la consulta sobre el Libro Blanco de la Comisión Europea sobre Inteligencia Artificial.
- — Consejo General de la Abogacía Española, Código Deontológico de la Abogacía Española, 1ª ed., Valencia (Tirant humanidades), 2022, pp. 28 a 35.
- — Consejo de la Unión Europea (2022) Reglamento de Inteligencia Artificial: el Consejo pide que se promueva una IA segura que respete los derechos fundamentales.
- — DOUGLAS HEAVEN, W., «Imágenes generadas por IA: la fea realidad sobre cómo se crean» en MIT Technology Review, pp. 1 a 3.
- — European Data Protection Board (2020) Directrices 5/2020 sobre el consentimiento en el sentido del Reglamento (UE) 2016/679 (LA LEY 6637/2016), pp. 8 a 9.
- — European Banking Authority (2020) EBA REPORT ON BIG DATA AND ADVANCED ANALYTICS.
- — FAILERO, J. C., «Limitar la dependencia algorítmica» en Nueva Sociedad, pp. 121 a 129.
- — FARIA, J.E. en El derecho en la economía globalizada, 1ª ed., Madrid (Trotta), 2001, pp. 99 a 100
- — FERNANDEZ BEDOYA, A., «Inteligencia artificial en los servicios financieros» en Boletín Económico de artículos analíticos 2/29, marzo 2019, p.3.
- — Grupo Independiente de Expertos de Alto Nivel sobre Inteligencia Artificial (2019) Directrices éticas para una I.A. fiable.
- — Grupo de Trabajo sobre Protección de Datos del artículo 29 (2017) Directrices sobre decisiones individuales automatizadas y elaboración de perfiles a los efectos del Reglamento 2016/679 (LA LEY 6637/2016).
- — Grupo de Trabajo sobre Protección de Datos del artículo 29 (2013) Dictamen 03/2013 sobre limitación de la finalidad.
- — Grupo de Trabajo sobre Protección de Datos del artículo 29 (2013) Dictamen 06/2013 sobre datos abiertos y reutilización de la información del sector público (ISP).
- — HASELTON, M.G., «Adaptive rationality: an evolution perspective» en Social Cognition, Vol. 27, No. 5, 2009, pp. 733-763
- — MARTÍN FERNÁNDEZ, B., «Claves para entender la propuesta de reglamento de Inteligencia Artificial», Revista Economist & Jurist, diciembre 2022, pp. 1 a 3.
- — MARTINEZ DEVIA, A., «La Inteligencia Artificial, el Big Data y la Era Digital: ¿Una amenaza para los datos personales?» en Revista de la Propiedad Inmaterial No 27. enero-junio 2019, p.7.
- — NEGRO, A., PÉREZ MACILLA, M. (Octubre de 2022) «La Comisión propone nuevas normas de responsabilidad en materia de inteligencia artificial», en Blog de Propiedad Intelectual y Tecnologías de Cuatrecasas.
- — O’NEIL, C., en Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy, 1ª ed., Nueva York (Random House LCC US), 2016, pp. 20 a 21.
- — PALMA ORTIGOSA A., «Decisiones automatizadas en el RGPD. El uso de algoritmos en el contexto de la protección de datos», en Revista General de Derecho Administrativo No 50, enero 2019, p. 4.
- — RUIZ-CANTERO. M, VERDÚ-DELGADO, M., «Sesgo de género en el esfuerzo terapéutico» en Gaceta sanitaria: Órgano oficial de la Sociedad Española de Salud Pública y Administración Sanitaria, Vol. 18, julio de 2004, pp. 118 a 125.
- — SMITH, B.; SHUM, H., en The future computed: Artificial Intelligence and its role in society, 1ª ed., Redmond, Washington (Microsoft Corporation), 2018, p. 33
VIII. Jurisprudencia
- — Sentencia del TJUE de 11 de noviembre de 2020 en el asunto C-61/19 (LA LEY 150649/2020).
- — Sentencia del TJUE de 24 de noviembre de 2011, asuntos C-468/10 (LA LEY 219518/2011) y C-469/10.
- — Sentencia del Tribunal Constitucional Español de 30 de noviembre del 2000, asunto 290/2000.
IX. Legislación
X. Resoluciones AEPD
- — Resolución del procedimiento sancionador PS/00070/2019 instruido por la Agencia Española de Protección de Datos, de enero de 2021 (asunto BBVA).
- — Resolución del procedimiento sancionador PS/00477/2019 instruido por la Agencia Española de Protección de Datos, de enero de 2021 (asunto CAIXABANK).